- ProdukteMES-Module f├╝r Gro├¤serien- und Massenproduktion. Erm├Čglicht die digitalen Transformation Ihrer Hightech-Fertigung.Desktop-Software zur Datenanalyse, entwickelt f├╝r Ingenieure. St├żrken Sie Ihr Team in der technischen Datenanalyse.Die innovative Software f├╝r F&E-Abteilungen als R├╝ckgrat f├╝r Ihr Wissensmanagement, damit Sie Produkte schneller auf den Markt bringen.Leistungsf├żhiges Manufacturing Execution System (MES) f├╝r Hersteller von Medizinprodukten und Medizinger├żten.
- Expertise
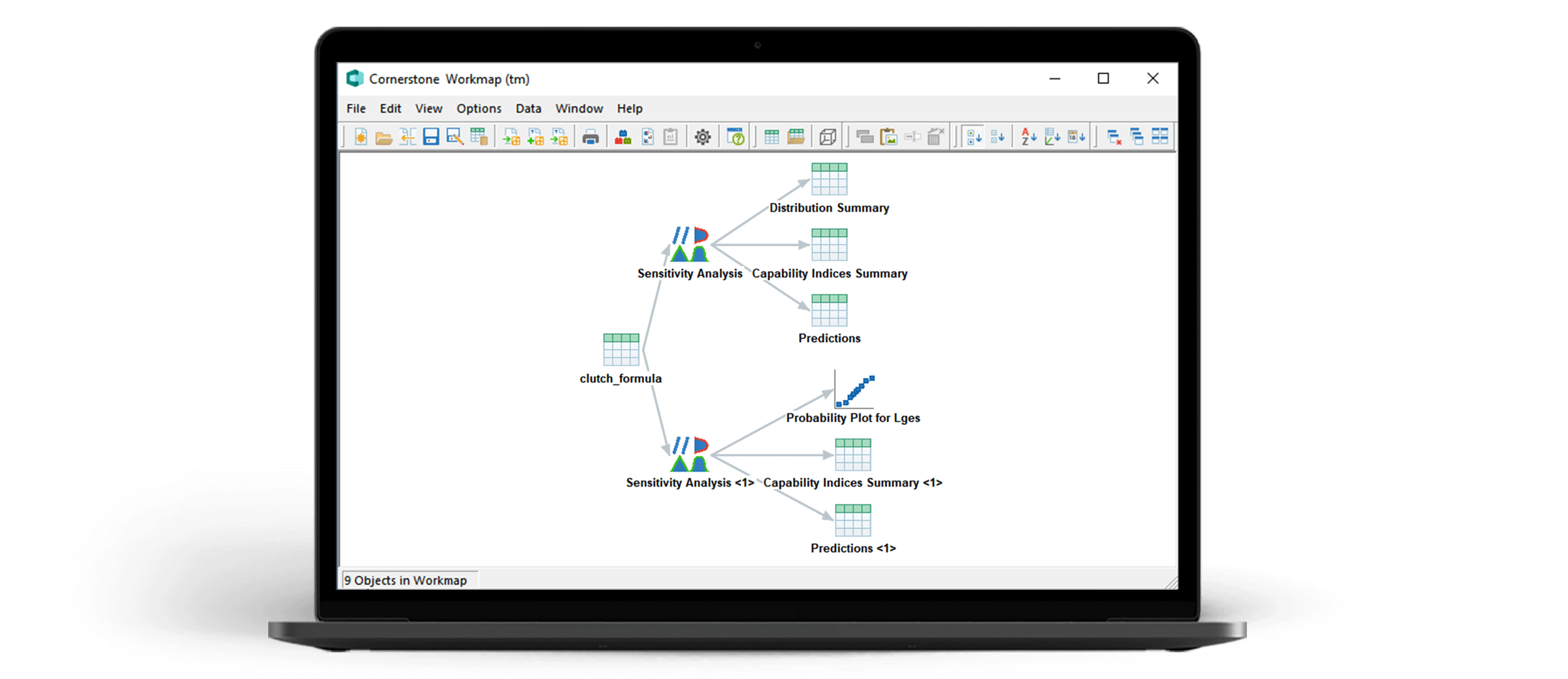
Profitieren Sie von der Leidenschaft und der jahrzehntelangen Erfahrung, die camLine jeden Tag in die Entwicklung seiner hauseigenen Softwarel├Čsungen steckt. Unsere Expertise erm├Čglicht einen schnelleren Datenzugriff, erh├Čht die Prozesssicherheit und verk├╝rzt die Reaktions- und Ausfallzeiten. Die Produkte sind in vier verschiedene Marken unterteilt, die Sie in allen Bereiche von der Innovation bis zur Produktion unterst├╝tzen.
- BranchenSeit mehr als 30 Jahren weltweit einer der Top Software-L├Čsungsanbieter in der Halbleiterindustrie.
Optimieren Sie mit unserer MES Software Ihre Produktion in der Elektronikbranche.
Bringen Sie Ihre Produktion auf die ├£berholspur.Top-Fertigungsl├Čsungen f├╝r eine gesunde Sache.
Vitale Systemlandschaft f├╝r agile Teams, die f├╝r hohen Datendurchsatz ausgelegt ist.
Sonnige Zeiten: Mit MES Solar bieten wir Ihnen eine abgestimmte L├Čsung.
Mehr Effizienz bei der Entwicklung von Fertigungstechnologien.Digitale Kontinuit├żt auf Hochspannung von der Technologieentwicklung bis zur Gigafactory.
- academy
Entdecken Sie unser vielf├żltiges Angebot mit unseren Experten.
Interaktives Lernen. Jederzeit. ├£berall. Eigenst├żndig.
Noch nicht registriert?
Login hier anfordern.Unser Team vermittelt Ihnen einzigartiges Expertenwissen und Know-how. - Karriere
Die Welt der Produktion ver├żndert sich rasant. Die Frage ist: Was tragen wir zur Industrie 4.0 bei? Die Antwort ist einfach: Bei camLine denken wir global und entwickeln schon heute die Fertigungs-Softwarel├Čsungen von morgen.
- Kontakt
Fraunhoferring 9
85238 Petershausen
Deutschland
Tel.: + 49 (0) 8137 935-0
E-Mail: info(@)camLine.comFalls Sie keinen Zugriff auf Ihr Support-Konto haben, rufen Sie bitte camLine an unter
Tel.: + 49 (0) 8137 935-0
oder schreiben Sie an
administration(@)camline.comAchtung:
Von Samstag, 16. Oktober 2021, 9 Uhr MESZ, bis etwa Sonntag, 17. Oktober 2021, 9 Uhr MESZ, ist das camLine Support Portal nicht verf├╝gbar. In dringenden F├żllen nutzen Sie bitte Ihre spezielle Hotline-Nummer oder +49 8137 6059 989. .Achtung:
Am Mittwoch, 27. April 2022, k├Čnnte Ihre spezielle Hotline-Nummer nicht verf├╝gbar sein. In dringenden F├żllen rufen Sie bitte +49 8137 935-0 an. - Mediacenter